Step 5. Execute Through The Pipeline
Step 5
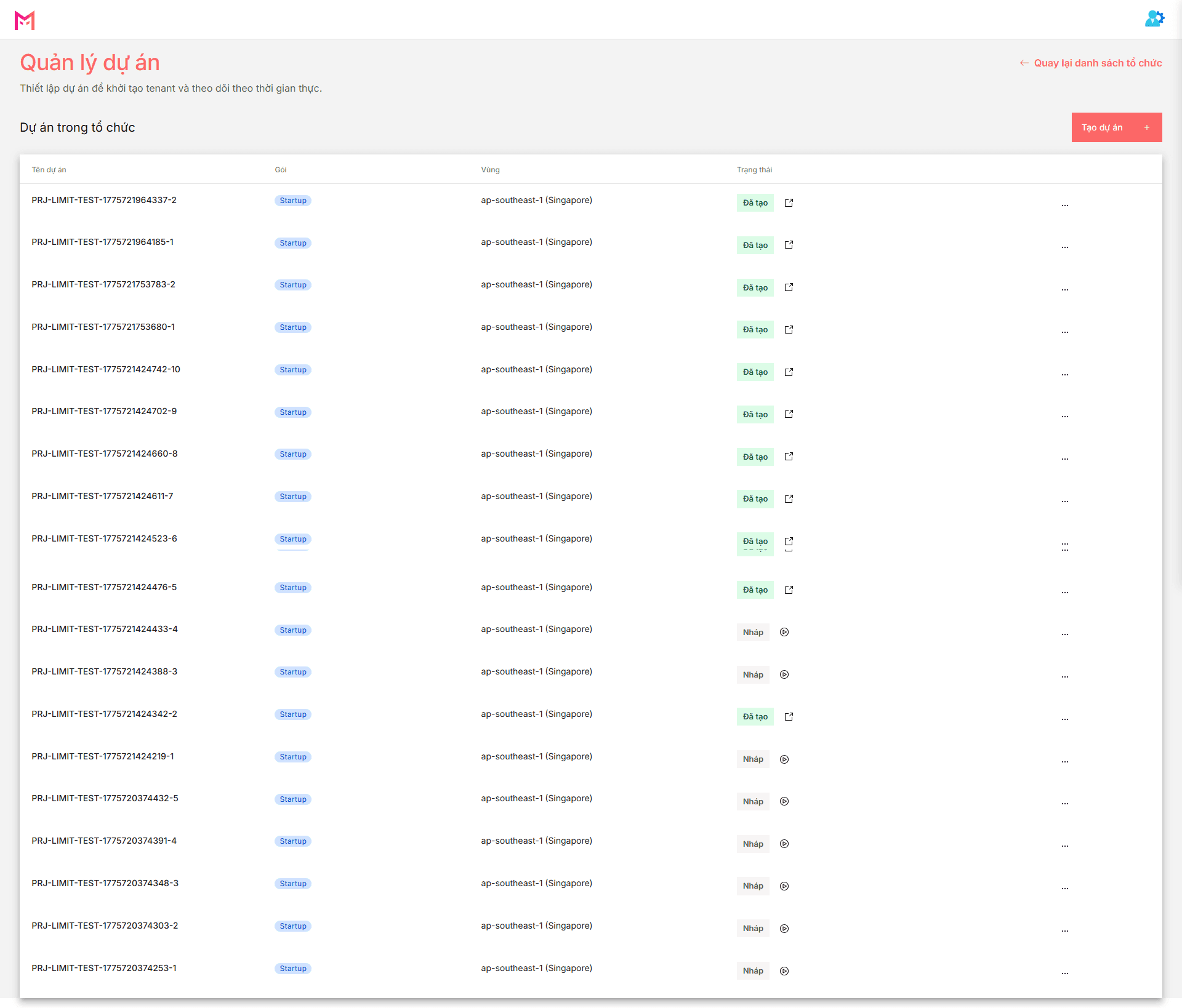
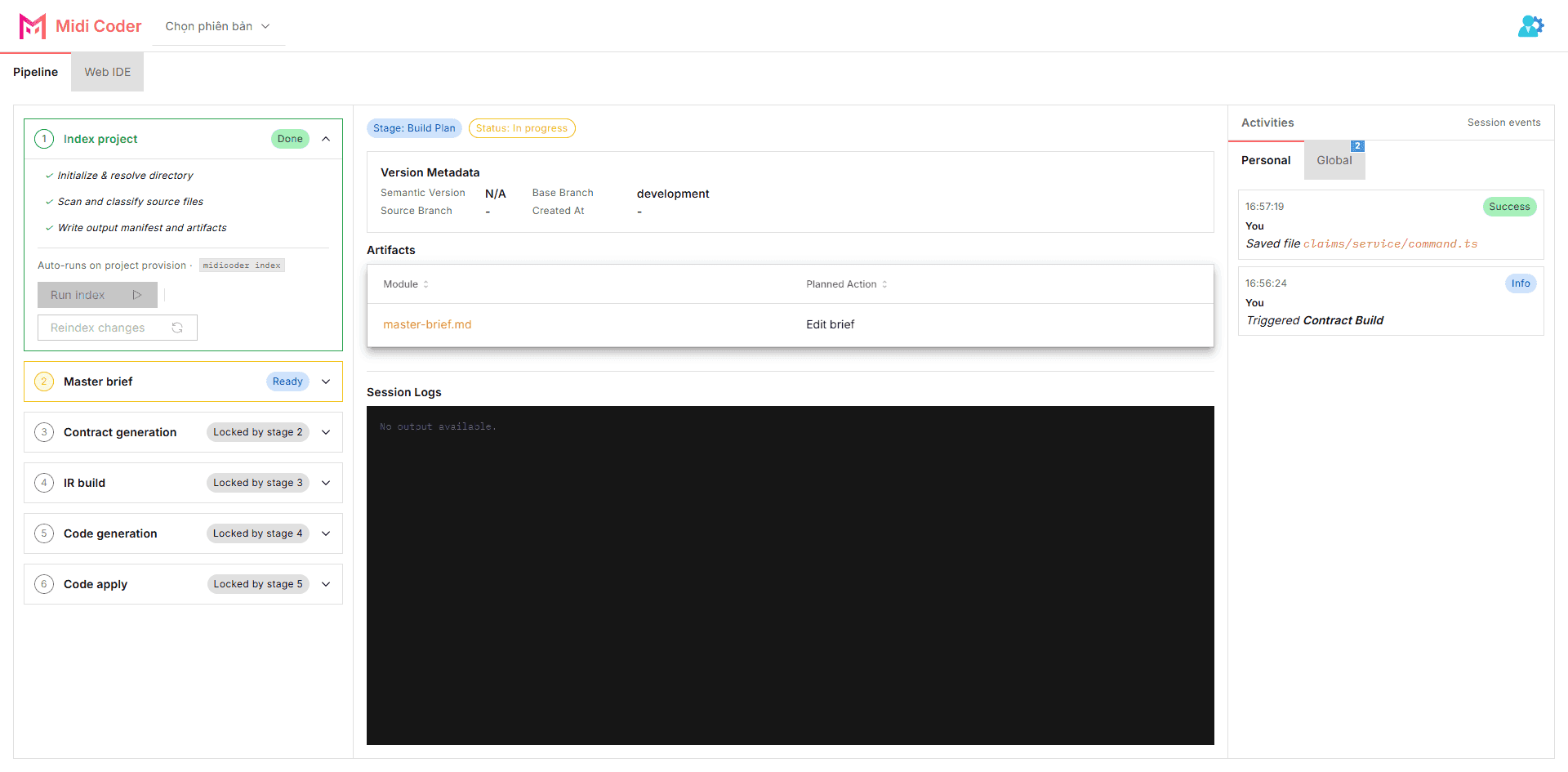
Once the first version has been created, the flow does not stop at having a new branch. From this point on, the system starts executing through the pipeline so the change moves through a sequence of stages, artifacts, and diffs that can be inspected.
At this step, the most important thing is to read the pipeline as a running flow, not as a decorative status row:
- the pipeline starts from the
index stage and continues through the remaining stages in the flow
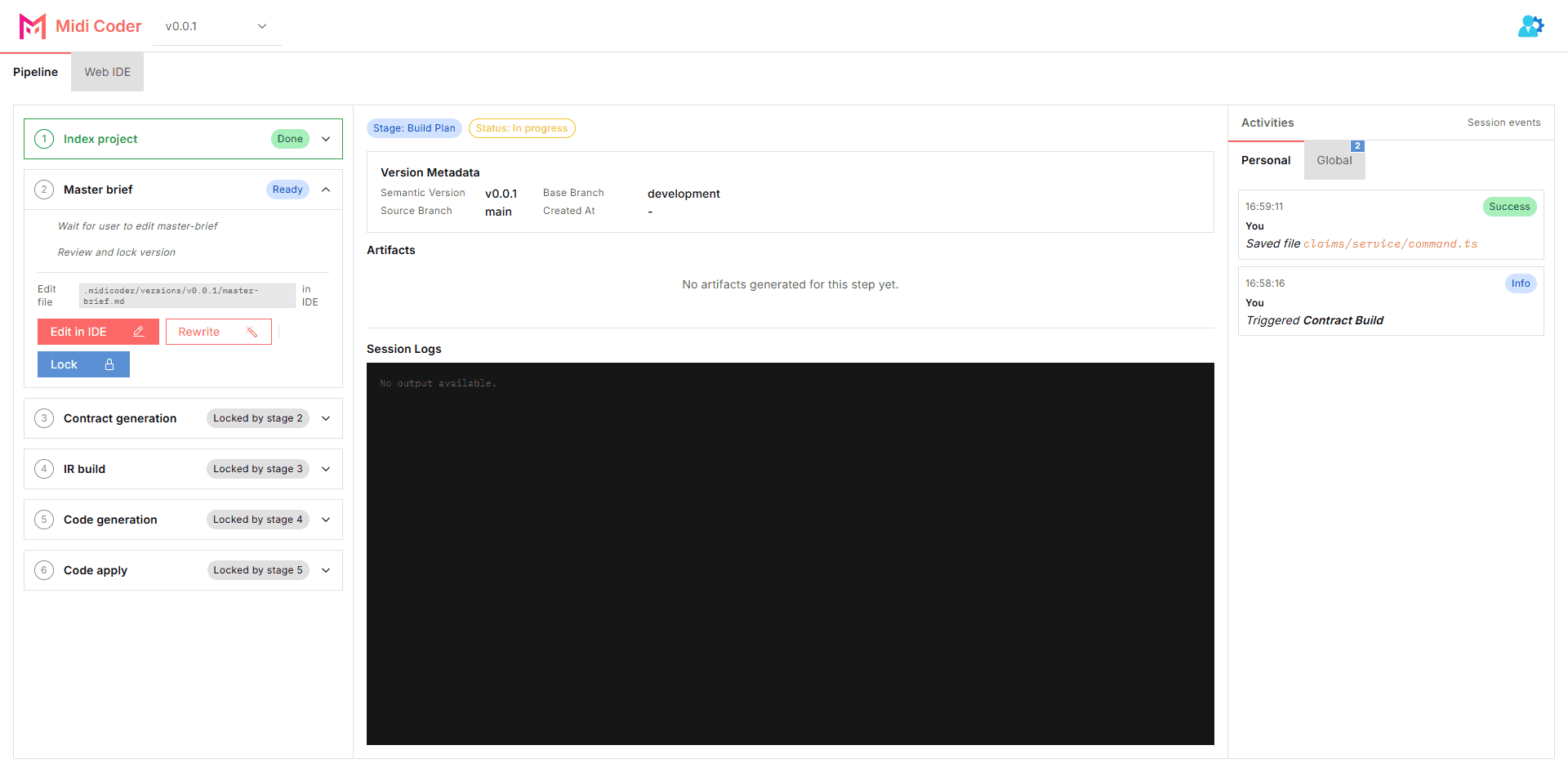
- each stage has its own state, and that state attaches directly to the version that is running
- artifacts appear along the way, including brief files, contract output, patches, and finally the
file diff at the code apply step
The important point here is that the value of the pipeline is not the final answer alone. The value is that you can see what the system is doing, which stage it is in, which artifacts already exist, and which diff is about to enter the codebase.
If step 4 gives the first change a concrete shape, step 5 turns that change into a flow that can be observed and reviewed. This is the point where state, artifacts, and diff begin connecting into one clear execution path.
The checkpoint for this step is simple: the pipeline is already running on the first version, the current stage is visible, artifacts have started to appear, and you can trace the flow from version to diff instead of waiting for a final output only.